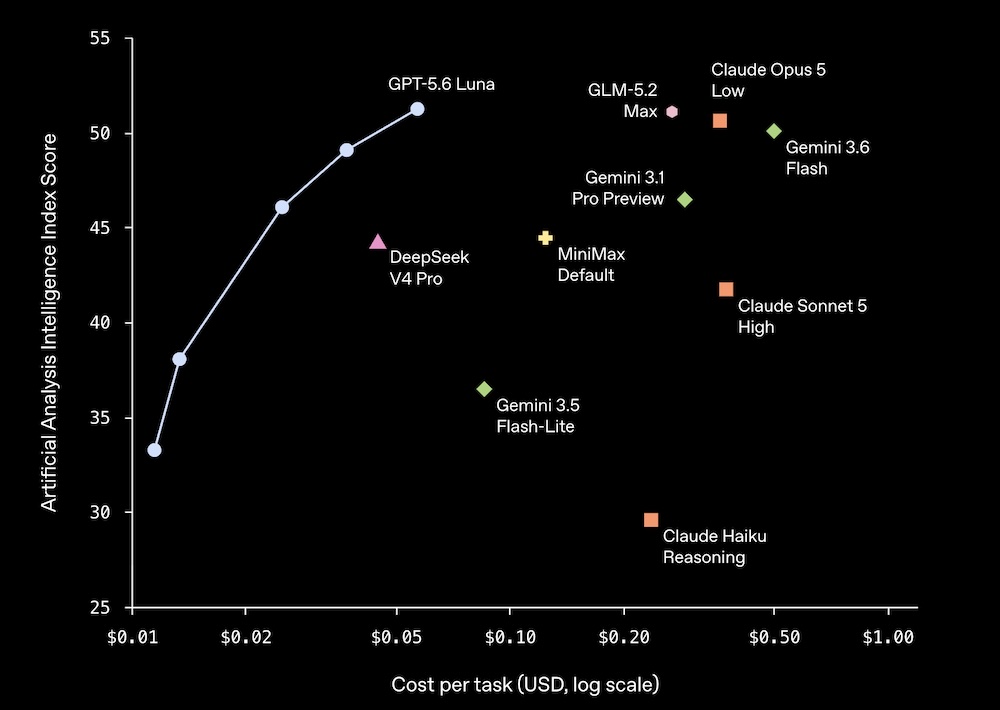
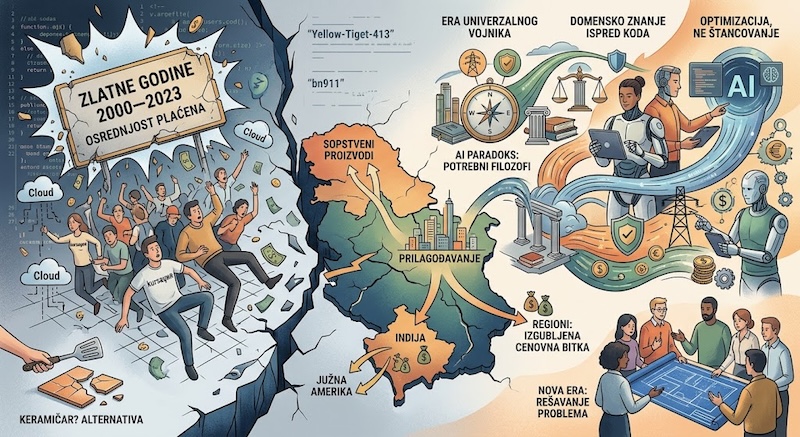
PlayStation 5 je na svom lansiranju 2020. godine koštao 399 dolara. Danas, uprkos tome što je reč o hardveru koji bi po svim zakonima tehnološkog ciklusa trebalo da pojeftini, njegova cena iznosi 599 dolara. Xbox je od 2025. godine tri puta korigovao cene naviše, dok Nintendo priprema teren za drastično skuplji Switch 2. Centralno pitanje za svakog analitičara nije samo gde je nestao jeftin hardver, već zašto on uopšte stari ako mu cena raste? Odgovor leži u brutalnoj tržišnoj distorziji izazvanoj usponom veštačke inteligencije. Gejming industrija se nalazi usred razorne "lančane reakcije" gde AI sektor operiše u režimu apsolutnog straha od zaostatka (FOMO), trošeći kapital koji obesmišljava tradicionalnu tržišnu utakmicu.