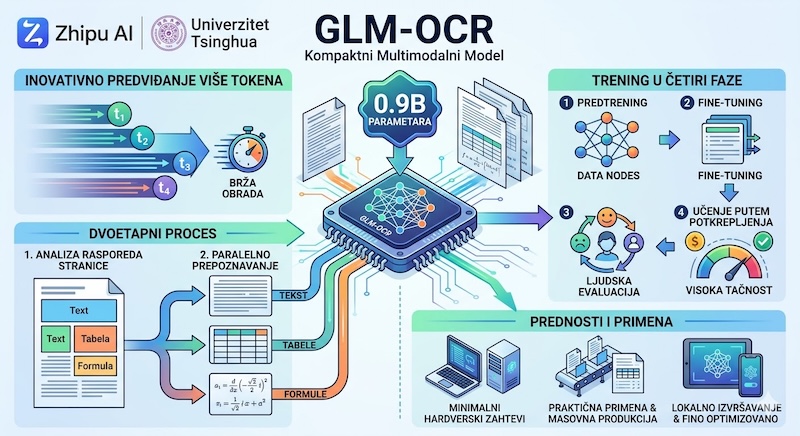
Tradicionalni OCR sistemi dugo su se suočavali sa nerešivim problemom: ili su previše jednostavni da bi obradili kompleksne rasporede elemenata na stranici, ili su toliko masivni da njihova primena zahteva ogromne procesorske resurse koji obesmišljavaju širu primenu. Kako učiniti OCR korisnim za stvarne dokumente, a ne samo za "čiste" demo slike, bez pretvaranja inferencije u finansijsku i energetsku katastrofu?