Kraj ere tromih i skupih OCR sistema
Tradicionalni OCR sistemi dugo su se suočavali sa nerešivim problemom: ili su previše jednostavni da bi obradili kompleksne rasporede elemenata na stranici, ili su toliko masivni da njihova primena zahteva ogromne procesorske resurse koji obesmišljavaju širu primenu. Kako učiniti OCR korisnim za stvarne dokumente, a ne samo za "čiste" demo slike, bez pretvaranja inferencije u finansijsku i energetsku katastrofu?
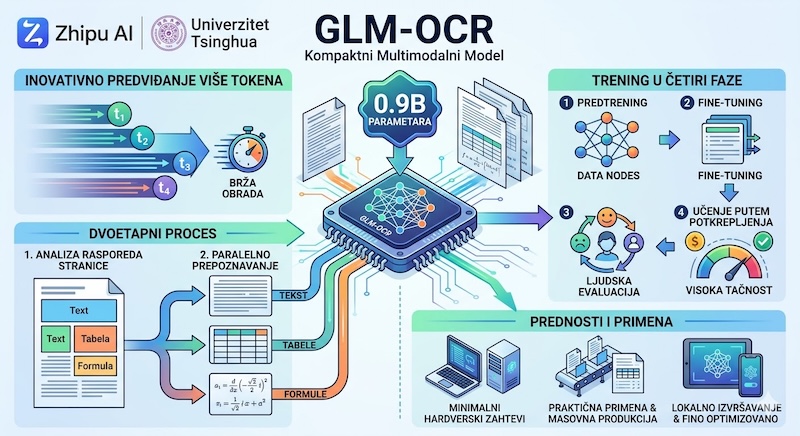
Odgovor stiže u obliku GLM-OCR modela, koji su razvili istraživači sa Univerziteta Tsinghua i kompanije Zhipu AI. Ključ njegove efikasnosti leži u pametno alociranoj arhitekturi od ukupno 0,9 milijardi parametara, koju čine 0,4B CogViT vizuelni enkoder i 0,5B GLM jezički dekoder. Ovaj kompaktni multimodalni sistem dokazuje da za vrhunske rezultate u digitalizaciji nije uvek potreban ogroman broj parametara, već njihova precizna specijalizacija.
MTP: Tehnologija koja predviđa budućnost teksta u hodu
Jedna od najznačajnijih tehničkih inovacija u GLM-OCR modelu je uvođenje Multi-Token Prediction (MTP) mehanizma. Dok standardni autoregresivni modeli generišu tekst token po token — što je proces koji značajno usporava rad kod determinističkih OCR zadataka — GLM-OCR je obučen da predviđa 10 tokena istovremeno u svakom koraku.
U realnim uslovima inferencije, model postiže prosek od 5,2 tokena po koraku generisanja, što rezultira povećanjem propusne moći (throughput) za približno 50% u poređenju sa tradicionalnim metodama. Razvojni tim u svom radu postavlja suštinsko pitanje o održivosti modernih rešenja:
„Šta je potrebno da OCR postane koristan za stvarne dokumente umesto čistih demo slika? I može li kompaktni multimodalni model da obradi parsiranje, tabele, formule i strukturiranu ekstrakciju bez pretvaranja inferencije u lomaču resursa?“
Korišćenjem šeme deljenja parametara među modelima, GLM-OCR uspeva da zadrži memorijske zahteve na minimalnom nivou, uprkos ovom paralelnom predviđanju tokena.
Arhitektura iz dva koraka: Prvo razumevanje, onda čitanje
Za razliku od generičkih multimodalnih modela koji pokušavaju da „čitaju“ stranicu linearno s leva na desno, GLM-OCR koristi sofisticirani proces u dve faze:
- Analiza rasporeda (Layout analysis): Prva faza koristi alat PP-DocLayout-V3 za preciznu identifikaciju strukturiranih regiona na stranici.
- Paralelno prepoznavanje: Nakon što se stranica dekomponuje na semantičke celine, model vrši paralelno prepoznavanje specifičnih regiona.
Ovakav pristup "čitanja s razumevanjem strukture" omogućava modelu da bude daleko robusniji pri obradi dokumenata sa kompleksnim elementima kao što su pečati, tabele, formule i kodni blokovi. Umesto da se oslanja na puko prepoznavanje karaktera, model razume logiku prostorne organizacije dokumenta.
Parsing vs. KIE: Različiti putevi za različite ciljeve
GLM-OCR pravi jasnu distinkciju između dva ključna zadatka, što je od presudnog značaja za automatizaciju poslovnih procesa:
- Parsiranje dokumenata: Fokusira se na pretvaranje vizuelnog sadržaja u strukturirane formate kao što su Markdown ili JSON kroz procesiranje pojedinačnih regiona identifikovanih u prvoj fazi.
- Ekstrakcija ključnih informacija (KIE): Za razliku od parsiranja, ovde se cela slika dokumenta šalje modelu uz specifičan „task prompt“, a model direktno generiše JSON sa traženim poljima (npr. samo datum, PIB i ukupan iznos sa fakture).
Ova podela omogućava korisnicima da biraju između verno digitalizovane kopije dokumenta i brze ekstrakcije preciznih podataka, optimizujući utrošak resursa u zavisnosti od krajnjeg cilja.
Trening sa nagradama: Kako RLHF oblikuje preciznost
Put do visoke preciznosti vodio je kroz rigorozan proces obuke u četiri faze. Posebno je značajna četvrta faza — učenje potkrepljivanjem (Reinforcement Learning) uz korišćenje GRPO (Group Relative Policy Optimization) algoritma.
Izbor GRPO-a je strateški: on omogućava visoke performanse poravnanja (alignment) modela bez ogromnih hardverskih troškova koje nosi tradicionalni PPO algoritam (jer eliminiše potrebu za teškim "value" modelom). Model se nagrađuje na osnovu egzaktnih metrika:
- Normalized Edit Distance za tekstualnu tačnost.
- CDM score za prepoznavanje formula.
- TEDS score za preciznost strukture tabela.
- Field-level F1 score za KIE zadatke.
Stroge kazne za loše formatirane JSON strukture ili nepotrebno ponavljanje teksta čine ovaj model izuzetno pouzdanim za produkciona okruženja gde je validnost izlaznih podataka imperativ.
Benchmark realnost: Šampion u svojoj kategoriji (uz ograde)
Rezultati testiranja potvrđuju da je GLM-OCR vodeći model u kategoriji ispod jedne milijarde parametara, postižući impresivnu brzinu od 0,67 slika u sekundi i 1,86 PDF stranica u sekundi.
- OmniDocBench v1.5: 94.6 (Lider u klasi)
- OCRBench (Text): 94.0
- UniMERNet (Formule): 96.5
- Handwritten-KIE: 86.1
- Nanonets-KIE: 93.7
Ipak, kao profesionalci moramo biti objektivni. Iako dominira u svojoj klasi, GLM-OCR ne pobeđuje u apsolutno svakoj disciplini. Na primer, model MinerU 2.5 i dalje drži prednost kod kompleksnih tabela na PubTabNet benchmarku (88.4 naspram GLM-OCR-ovih 85.2), dok giganti poput Gemini-3-Pro zadržavaju prednost u specifičnim zadacima ekstrakcije informacija (KIE) gde su korišćeni kao referentni modeli.
Zaključak: Budućnost OCR-a je na ivici (Edge)
Značaj GLM-OCR-a ne leži samo u arhitekturi, već u njegovoj spremnosti za trenutnu implementaciju. Sa podrškom za vLLM, SGLang i Ollama, model je lako integrabilan u postojeće sisteme. Uz cenu od svega 0,2 RMB po milionu tokena preko MaaS API-ja, on predstavlja jedno od najisplativijih rešenja na tržištu danas.
Kombinacija niske cene, malih hardverskih zahteva i visoke preciznosti postavlja provokativno pitanje: Da li smo konačno stigli do tačke gde svaki uređaj može imati moć profesionalnog arhiviste u svom džepu? Sudeći po performansama GLM-OCR-a, ta budućnost više nije pitanje mogućnosti, već samo implementacije.
Izvor: marktechpost.com

Komentari
Nema komentara. Šta vi mislite o ovome?