Zašto Qwen3.5-9B dominira
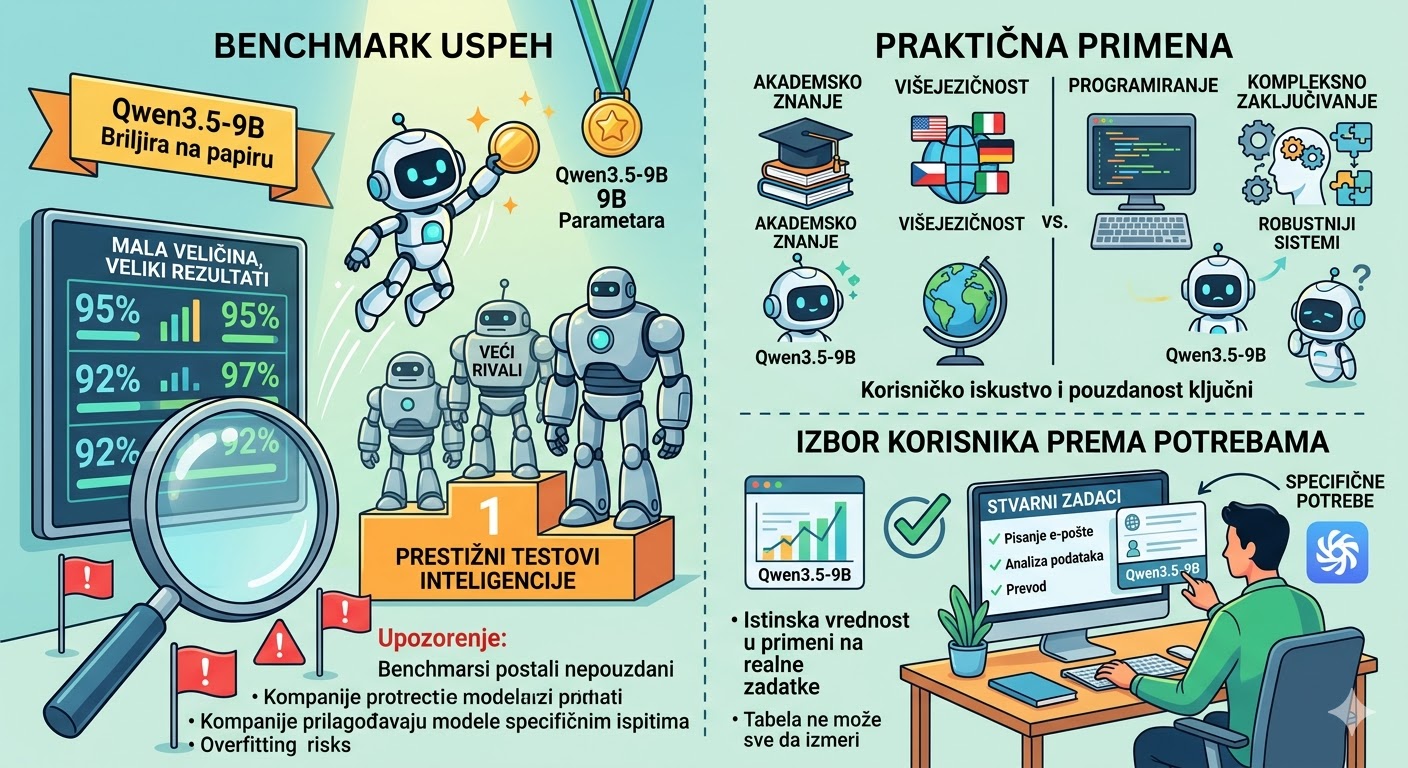
U AI zajednici trenutno vlada veliko uzbuđenje zbog narativa koji podseća na modernu verziju borbe Davida protiv Golijata. Model Qwen3.5-9B, sa svega 9 milijardi parametara, uspeo je da na prestižnim testovima nadmaši gigante poput modela gpt-oss-120b, koji je više nego deset puta veći. Priča o otvorenom kodu koji pobeđuje bez potrebe za ogromnim data centrima brzo se proširila, obećavajući vrhunske performanse na hardveru koji je dostupan prosečnom entuzijasti.
Međutim, dok su ovi rezultati inženjerski impresivni, postavlja se suštinsko pitanje: da li ovi brojevi zaista odražavaju svakodnevno iskustvo korišćenja modela ili je reč o optimizaciji za "igranje sa brojevima"? Da bismo razumeli stvarnu vrednost ovog modela, moramo dekodirati arhitekturu i metodologiju iza ovih rang-lista.
Kriza kredibiliteta u svetu benchmarkinga
Trenutna kultura testiranja AI modela suočava se sa dubokim problemom poverenja. Postao je standard da svaki novi model prati grafikon koji ga postavlja na sam vrh liste, ali korisnici u praksi često primećuju da se to iskustvo ne prenosi u realan rad. Ovaj jaz nastaje jer su laboratorije počele da optimizuju modele specifično za metriku testova, a ne za širu upotrebnu vrednost.
Kao primer ove krize izdvaja se Meta i njihov model Llama 4. Kompanija je bila kritikovana zbog slanja "eksperimentalne chat" verzije na testiranje koja se razlikovala od javno dostupnog modela. Kasnije je potvrđeno da su rezultati bili "doterivani" (fudged) korišćenjem različitih iteracija modela za različite benchmark testove kako bi se veštački kreirala slika o superiornosti. U takvom okruženju, tabele prestaju da budu objektivan vodič.
„Samopouzdanje pobeđuje preciznost, a formatiranje pobeđuje činjenice.“ — SurgeAI analiza o načinu na koji modeli dobijaju glasove na rang-listama.
Šta zapravo znače rezultati na GPQA Diamond i MMLU-Pro?
Qwen3.5-9B je postigao zapažene rezultate na testovima koji se smatraju "zlatnim standardom" rezonovanja. Na GPQA Diamond testu ostvario je 81.7 naspram 80.1 kod gpt-oss-120b. Na MMLU-Pro testu vodi sa 82.5 naspram 80.8, dok na višejezičnom MMMLU testu beleži 81.2 naspram 78.2. Ovi brojevi su omogućeni primenom hibridne arhitekture koja kombinuje Gated Delta Networks sa sparse Mixture-of-Experts (MoE) sistemom, što je izuzetno efikasno inženjersko rešenje.
Ipak, pobeda u ovim uskim naučnim domenima ne garantuje opštu superiornost. GPQA Diamond, na primer, sadrži svega 198 pitanja iz biologije, fizike i hemije koja su sastavili doktori nauka. To je "Google-proof" test za duboko akademsko rezonovanje, ali tako mali uzorak nije dovoljan da se proglasi apsolutni pobednik u opštoj inteligenciji. MMLU-Pro, iako širi, i dalje je test višestrukog izbora (multiple-choice), što ne oslikava realne zadatke poput pisanja mejlova ili kreativnog rešavanja problema.
Gde "mališa" gubi trku: Kodiranje i kompleksno rezonovanje
Kada se fokus pomeri sa teorijskih testova na praktičnu primenu, veći modeli i dalje zadržavaju značajnu prednost, posebno tamo gde je potreban dugačak logički lanac.
Slabije performanse u kodiranju Na testu LiveCodeBench, gpt-oss-120b dominira sa 82.7 poena, dok Qwen3.5-9B dostiže 65.6. Sličan odnos snaga vidljiv je i na OJBench-u (41.5 naspram 29.2). Ovi testovi su ključni jer generisanje koda nije samo zadatak za programere; sposobnost kodiranja je proksi (zastupnik) za sposobnost rezonovanja i pozivanja alata (tool calling).
Ključni faktori za agente Ako planirate da model koristite kao agenta koji treba da koristi eksterne alate, stabilnost koju pruža veći model je nezamenljiva. Manji modeli često gube nit kod kompleksnih instrukcija, što ih čini manje pouzdanim za automatizaciju radnih procesa, uprkos visokim ocenama na akademskim testovima znanja.
Subjektivni "osećaj" naspram suvih cifara
Brojevi na tabeli ne mogu da kvantifikuju "osećaj" u radu — kako model reaguje na dvosmislene upite ili kako se ponaša u dugom kontekstu. Ovde se najbolje vidi razlika između generaliste kao što je Qwen3.5-9B i specijalizovanih modela poput Qwen3-Coder-Next.
Qwen3-Coder-Next ima ukupno 80 milijardi parametara, ali aktivira samo 3 milijarde, što ga čini ultra-efikasnim. Njegova stvarna prednost ne dolazi iz pogađanja odgovora na testovima, već iz procesa obuke zasnovanog na reinforcement learning-u (učenje putem potkrepljenja) kroz direktnu interakciju sa kodnim okruženjima. Za razliku od opšteg modela koji bira tačan odgovor pod slovom "C", specijalizovani model je naučen da izvršava zadatke i ispravlja sopstvene greške u hodu, što ima daleko veću praktičnu vrednost za krajnjeg korisnika.
Zaključak: Birajte model prema svom radnom toku (workflowu)
Qwen3.5-9B je izuzetan dokaz napretka u optimizaciji manjih modela, omogućavajući vrhunski AI na skromnijem hardveru. Međutim, izbor modela mora biti vođen vašim specifičnim potrebama — bilo da je to ograničen VRAM, potreba za preciznim pozivanjem alata ili rad na specifičnom jeziku — a ne isključivo pozicijom na rang-listi.
Kada ste poslednji put testirali model na svom realnom, svakodnevnom zadatku umesto da slepo verujete grafikonu sa društvenih mreža? U svetu gde se rezultati često doteruju, vaše lično testiranje je jedini relevantan benchmark.
Izvor: XDA

Komentari
Nema komentara. Šta vi mislite o ovome?