Pet malih jezičkih modela za agentsko pozivanje alata
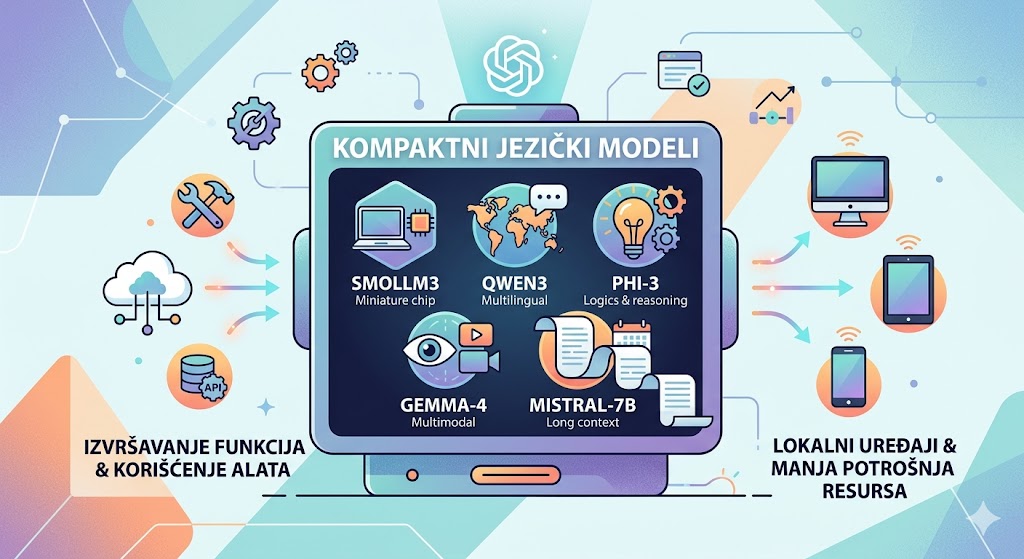
Ovaj tekst predstavlja pregled pet kompaktnih jezičkih modela otvorenog koda koji su specijalizovani za izvršavanje funkcija i korišćenje alata u okviru autonomnih AI sistema. Autor ističe da modeli poput SmolLM3, Qwen3, Phi-3, Gemma-4 i Mistral-7B omogućavaju efikasan rad na lokalnim uređajima uz značajno manju potrošnju resursa u poređenju sa velikim sistemima. Svaki model nudi specifične prednosti, od multimodalnih mogućnosti i podrške za više jezika do naprednog logičkog zaključivanja i rada sa dugim kontekstom. Ovi tehnološki alati premošćuju jaz između kompleksnih potreba veštačke inteligencije i ograničenog hardvera, čineći napredne funkcije dostupnijim programerima. Kroz analizu njihovih arhitektura i licenci, tekst služi kao vodič za odabir najprikladnijeg rešenja za automatizovane radne tokove i lokalnu primenu.
1. Uvod: Kraj ere "velikih modela" kao jedinog rešenja
Dugo je u Silicijumskoj dolini vladala dogma: veće je uvek bolje. Verovalo se da su masivni "frontier" modeli, poput onih koji pokreću ChatGPT ili Claude, jedini put ka istinskoj inteligenciji. Međutim, realnost primene u stvarnom svetu donela je oštre lekcije. Visoki troškovi po svakom tokenu, neprihvatljiva latencija i zavisnost od ogromnih data centara čine ove gigante nepraktičnim za agilne, lokalne aplikacije.
Danas svedočimo tektonskom poremećaju. Era "malih jezičkih modela" (SLM) nije samo utešna nagrada za one sa slabijim hardverom; to je rađanje suverene inteligencije (Sovereign Intelligence). Više nije reč samo o tome da AI "priča" sa nama, već da "dela". Sposobnost za agentičko pozivanje alata (tool calling) na lokalnim uređajima znači da inteligencija prelazi iz oblaka direktno na "ivicu" (edge) – u vaše telefone, IoT senzore i privatne servere. Ovi modeli omogućavaju sistemima da samostalno biraju alate i izvršavaju funkcije bez slanja ijednog bajta podataka na tuđe servere.
2. Gemma-4-E2B-it: Multimodalni šampion koji staje u džep
Gemma-4-E2B-it iz Google DeepMind laboratorije predstavlja čudo inženjerske optimizacije. Dok njena puna struktura broji 5,1 milijardu parametara, ona koristi inovativnu arhitekturu koja je čini efikasnom kao model od 2,3 milijarde parametara. Uz pametnu kvantizaciju, ovaj model može da operiše sa manje od 1,5 GB memorije, otvarajući vrata agentičkoj inteligenciji na najosnovnijim uređajima.
Ono što Gemmu 4 izdvaja je njena sposobnost da "vidi i čuje" svoje okruženje kako bi preduzela akciju. Ona nije samo tekstualni procesor; ona nativno razume slike, audio zapise do 30 sekundi i video (kroz analizu frejmova). Zahvaljujući hibridnoj pažnji (kombinacija sliding window i global attention) i prozorčiću konteksta od 128k tokena, Gemma zadržava duboku svest o zadatku dok održava munjevitu brzinu inference.
"PLE (Per-Layer Embeddings) mehanizam dodaje namenski kondicioni vektor svakom sloju dekodera. Upravo ova inovacija omogućava E2B modelu da zadrži duboku svest neophodnu za složene zadatke uz minimalan memorijski otisak."
Promena licence na Apache 2.0 čini ovaj multimodalni dragulj dostupnim za komercijalnu upotrebu bez straha od pravnih restrikcija.
3. SmolLM3-3B: Pomeranje granica uz "Dual-mode" razmišljanje
Hugging Face je sa modelom SmolLM3-3B dokazao da veličina parametara nije jedino merilo snage. Treniran na kolosalnih 11,2 biliona (T) tokena kroz strogo kuriran nastavni plan (web, kod, matematika), ovaj model od 3 milijarde parametara nudi nivo logike koji je ranije bio rezervisan za modele deset puta veće mase.
Fascinantna je primena NoPE (No Positional Embeddings) arhitekture, što je tehnički kuriozitet koji optimizuje performanse. Još važnije za agente je njegovo "dual-mode" razmišljanje. Korisnik može uključiti ili isključiti "thinking" režim (on-demand Chain-of-Thought). Ovo je ključno za agentičku efikasnost: model može "duboko razmisliti" pre nego što pozove kompleksnu Python funkciju, ili odgovoriti trenutno kada je reč o jednostavnom JSON formatiranju. Sa nativnim kontekstom od 64k (proširivo do 128k putem YaRN-a), SmolLM3 je idealan mozak za lokalne RAG sisteme.
4. Qwen3-4B-Instruct-2507: Multijezički gigant niskog kašnjenja
Alibaba (Qwen tim) nastavlja da dominira u sferi otvorenih modela, a Qwen3-4B je njihov odgovor na potrebu za globalnom, brzom inteligencijom. Podržavajući više od 100 jezika, ovaj model je optimizovan za direktne, "non-thinking" odgovore, što ga čini savršenim za korisničku podršku gde je latencija neprijatelj broj jedan.
Njegova prava snaga leži u "agentičkoj memoriji". Sa nativnim prozorom konteksta od neverovatnih 262.144 tokena, Qwen3 može da drži čitave biblioteke dokumentacije u svojoj aktivnoj radnoj memoriji dok pretražuje alate putem MCP (Model Context Protocol) servera.
Ključna tehnička unapređenja:
- Arhitektura: Kauzalni jezički model sa 36 transformatorskih slojeva.
- GQA (Grouped Query Attention): Implementacija sa 32 upitne glave i 8 KV glava za ekstremno efikasno upravljanje memorijom pri dugim kontekstima.
- Integracija: Nativna podrška za Qwen-Agent okvir koji interno rešava kompleksnost parsiranja alata.
5. Mistral-7B-Instruct-v0.3: Standard pouzdanosti u svetu otvorenog koda
Ako postoji model koji možemo nazvati "kičmom lokalnog AI pokreta", onda je to Mistral-7B. Verzija v0.3 donosi prefinjenost koja ga čini najpouzdanijim izborom za ozbiljne produkcione sisteme. Iako je sa 7,25 milijardi parametara najveći na ovoj listi, on i dalje udobno stoji na modernim radnim stanicama.
Mistral je uveo standardizovan način pozivanja funkcija putem specifičnih kontrolnih tokena (TOOL_CALLS, AVAILABLE_TOOLS). Njegova upotreba SWA (Sliding Window Attention) mehanizma omogućava mu da efikasno procesira sekvence, dok v3 tokenizer i prošireni vokabular od 32.768 tokena garantuju preciznost u kodu i jeziku. Njegova sveprisutnost na platformama poput Ollama i vLLM svedoči o tome da je Mistral postao univerzalni jezik za lokalne agente.
6. Phi-3-mini-4k-instruct: Mala pamet inspirisana kvalitetnim podacima
Microsoftov Phi-3-mini je živi dokaz vizionarske ideje da "kvalitet podataka pobeđuje kvantitet". Treniran na visokokvalitetnim sintetičkim podacima koji su "gusti" logičkim strukturama, ovaj model od 3,8B parametara u testovima logičkog zaključivanja često nadmašuje legendarne modele poput GPT-3.5.
Iako ima ograničenje od 4k konteksta, to je svestan inženjerski kompromis. Phi-3-mini je dizajniran da bude hirurški precizan alat za logiku i matematiku u okruženjima gde je memorija najskuplji resurs. Uz MIT licencu, on predstavlja najpermisivnije rešenje za kompanije koje žele da integrišu vrhunsku pamet u svoje zatvorene, komercijalne ekosisteme bez ikakvih ograničenja.
7. Zaključak: Demokratija inteligencije na ivici mreže
Pojava ovih modela označava novu eru: sposobni agentički sistemi više ne zahtevaju masivnu infrastrukturu niti duboke džepove za API troškove. Od potpuno transparentnog SmolLM3, koji nudi uvid u same podatke na kojima je građen, do multimodalnog Gemma 4 modela koji "oseća" svet, moć je vraćena u ruke programera.
Budućnost u kojoj svaki uređaj poseduje sopstvenu, lokalnu inteligenciju više nije vizija – to je realnost koja se dešava sada. "On-device" suverenitet menja pravila igre, pružajući nam brzinu i privatnost koju oblak nikada neće moći da ponudi.
Ako vaš frižider ili telefon može da izvršava složene zadatke i donosi odluke bez slanja podataka u oblak, kako će to promeniti vašu percepciju privatnosti i brzine veštačke inteligencije?
Izvor: kdnuggets.com
Komentari
Nema komentara. Šta vi mislite o ovome?