Google Cloud Knowledge Catalog: Univerzalni kontekst za veštačku inteligenciju
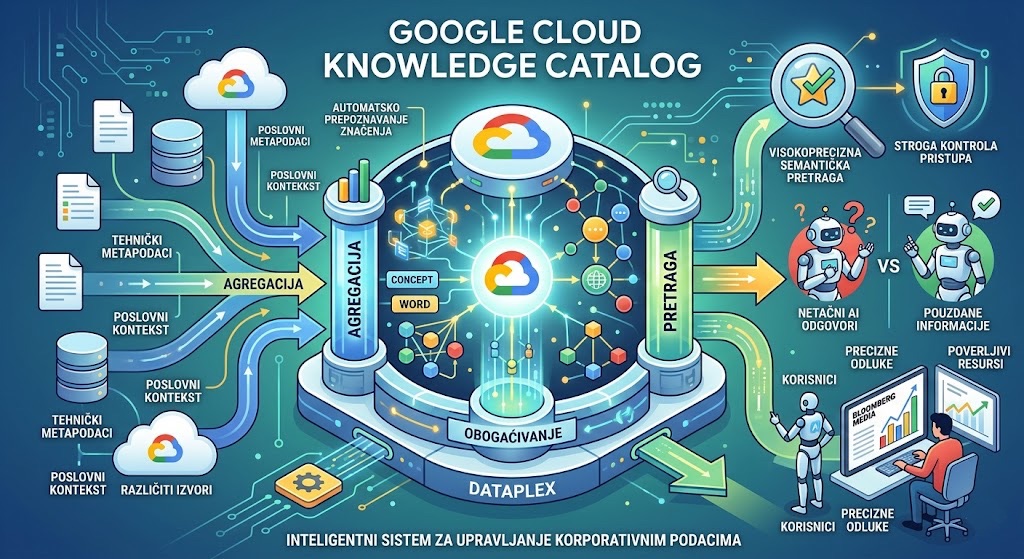
Google Cloud Knowledge Catalog predstavlja inovativnu evoluciju platforme Dataplex, dizajniranu da služi kao centralni inteligentni sistem za upravljanje korporativnim podacima. Ovaj alat rešava problem netačnih odgovora veštačke inteligencije tako što objedinjuje tehničke metapodatke i poslovni kontekst iz različitih izvora u jedinstvenu bazu znanja. Kroz tri ključna stuba — agregaciju, obogaćivanje i pretragu — sistem automatski prepoznaje značenje podataka i njihove međusobne odnose. Korisnici poput kompanije Bloomberg Media već koriste ove mogućnosti kako bi omogućili svojim AI agentima donošenje preciznih odluka zasnovanih na proverenim institucionalnim informacijama. Na kraju, platforma nudi visokopreciznu semantičku pretragu uz strogu kontrolu pristupa, transformišući sirove podatke u pouzdane resurse spremne za primenu u radnom okruženju.
Zašto je Google Cloud Knowledge Catalog prekretnica za vaše poslovanje
1. Problem "izgubljenog u prevodu" kod veštačke inteligencije
U svetu modernog poslovanja, uvođenje veštačke inteligencije često nailazi na nevidljivu prepreku: nedostatak konteksta. Mnogi AI agenti, uprkos svojoj procesorskoj snazi, pružaju netačne odgovore ili "haluciniraju" jer jednostavno ne razumeju specifičnu poslovnu logiku organizacije u kojoj rade.
Tradicionalni katalozi podataka, koji su godinama služili kao manuelni inventari tabela za tehničke korisnike, postali su usko grlo. Oni se fokusiraju na strukturu tabela, a ne na duboki kontekst i poslovnu semantiku koju AI zahteva. Pitanje koje se postavlja pred lidere je jasno: zašto vaša veštačka inteligencija i dalje pokušava da pogodi pravila vašeg poslovanja umesto da se oslanja na proverene činjenice?
2. Kraj ere ručnog popisa: Evolucija u "Universal Context Engine"
Google Cloud transformiše Dataplex u dinamičan, uvek aktivan Universal Context Engine (univerzalni motor za kontekst) pod nazivom Knowledge Catalog. Ova tranzicija označava kraj ere u kojoj su katalozi bili samo pasivne liste podataka namenjene isključivo inženjerima.
Za razliku od starog pristupa koji je zahtevao mukotrpno ručno popisivanje svake tabele, Knowledge Catalog služi kao živa osnova koja AI agentima omogućava izvršavanje kompleksnih zadataka sa matematičkom preciznošću. Danas agenti zahtevaju više od pukog uvida u šemu baze; njima je potrebna "poslovna semantika" — razumevanje značenja podataka i njihovih međusobnih odnosa kako bi se eliminisali zastareli uvidi i visoka latencija.
3. Tačka 1: Agregacija bez silosa – Od SAP-a do BigQuery-ja
Da bi se izgradio istinski kontekst, metapodaci moraju biti objedinjeni iz svakog kutka organizacije. Knowledge Catalog agresivno prikuplja tehničke i poslovne metapodatke, obezbeđujući jedinstven, upravljan izvor istine.
Izvori metapodataka uključuju:
- Native Google rešenja (GA/Preview): BigQuery, AlloyDB, Spanner, Cloud SQL, Firestore (Preview) i Looker (Preview).
- Enterprise Connectivity (Preview): Putem federacije konteksta, katalog ima uvid u sisteme kao što su SAP, Salesforce Data360, Palantir, ServiceNow i Workday.
- Partnerski katalozi (GA): Integracije sa alatima kao što su Atlan, Collibra, Datahub, Ab Initio i Anomalo.
Ključna inovacija u ovom stubu su LookML Agent i BigQuery measures (Preview). LookML Agent autonomno čita vašu strategijsku dokumentaciju kako bi generisao semantiku spremnu za poslovanje, dok BigQuery measures integrišu programsku poslovnu logiku direktno u SQL engine. Ovo osigurava da agenti koriste iste definicije i kalkulacije kao i vaši najbolji analitičari.
"Objedinjavanjem metapodataka i poslovnog konteksta Bloomberg Media kompanije kroz Knowledge Catalog, uspešno smo lansirali naš Data Access AI Agent. Ovo rešenje omogućava našim korisnicima da intuitivno istražuju naš data lake, pretvarajući složene poslovne upite u trenutne narative vođene veštačkom inteligencijom. Ključno je to što utemeljivanjem naše AI u poverljivom institucionalnom kontekstu osiguravamo poverenje u tačnost i kvalitet svakog generisanog uvida." — William Anderson, CTO, Bloomberg Media
4. Tačka 2: Automatsko obogaćivanje – Kada podaci sami pričaju svoju priču
Knowledge Catalog uvodi koncept kontinuiranog učenja, što fundamentalno menja upravljanje informacijama. Kroz funkcije kao što su Smart Storage i Object Context API (Preview), proces katalogizacije postaje proaktivan.
Kada nestruktuirani podaci stignu u Google Cloud Storage, oni se automatski taguju i obogaćuju metapodacima. Koristeći Gemini modele kroz "Deep multimodal metadata extraction", sistem identifikuje poslovne entitete i mapira kompleksne odnose direktno iz dokumenata ili slika.
Ovo je moćan pomak: podaci više ne čekaju na čoveka da ih opiše; oni se sami kategorišu i generišu sopstvenu poslovnu istoriju čim postanu dostupni u oblaku.
5. Tačka 3: Search kao novi "Query Path" za autonomne agente
U eri autonomnih agenata, pretraga je primarni put do informacija. Knowledge Catalog koristi high-precision semantic search (GA) zasnovan na decenijama Google inovacija u rangiranju i razumevanju namere korisnika.
Ova tehnologija nudi tri ključne prednosti:
- Sub-second latency: Agenti dobijaju relevantan kontekst u realnom vremenu.
- Access control-aware search: Globalna pretraga strogo poštuje dozvole iz izvornih sistema, osiguravajući da agenti vide samo ono za šta su ovlašćeni.
- Robust evaluation framework: Ovaj okvir omogućava timovima da kvantitativno testiraju i iteriraju na strategijama konstrukcije konteksta, pretvarajući optimizaciju u merljivu disciplinu.
6. Tačka 4: Eliminacija halucinacija putem "Verified Queries" i zaštitnih ograda
Jedan od glavnih razloga neuspeha AI projekata je halucinirana SQL logika. Knowledge Catalog rešava ovaj problem uvođenjem proverenih SQL obrazaca (verified queries) i semantičkih zaštitnih ograda (guardrails).
Katalog nudi unapred definisane obrasce i prirodno-jezička pitanja koja su ljudski verifikovana. Ovo služi kao kritičan most za poslovne korisnike: AI više ne pogađa kako da spoji tabele, već koristi proverenu logiku. Izgradnja poverenja u podatke više nije opciona; ona je inženjerski osigurana.
7. Tačka 5: Data Products kao gradivni blokovi AI budućnosti
Da bi AI postao pouzdan na nivou cele organizacije, podaci se moraju tretirati kao gotovi proizvodi. Data Products (GA) su samostalni paketi koji sadrže podatke, ugrađene SLA (ugovore o nivou usluge), pravila upravljanja i jasnu poslovnu namenu.
Ovakvo pakovanje konteksta zajedno sa podacima jedini je način da se kompleksni AI slučajevi skaliraju. Umesto da agent svaki put iznova uči pravila, on koristi gotov "Data Product" koji mu garantuje preciznost informacija potrebnih za rad u produkciji.
8. Zaključak: Od nagađanja do inženjerske discipline
Uvođenjem Google Cloud Knowledge Catalog-a, konstrukcija poslovnog konteksta prestaje da bude "igra nagađanja" i postaje egzaktna inženjerska disciplina. Data Products, visokoprecizna pretraga i semantičke zaštitne ograde čine finalne delove slagalice koji omogućavaju skaliranje AI rešenja uz maksimalnu pouzdanost.
Da li vaši AI agenti trenutno rade na osnovu činjenica ili samo nagađaju pravila vašeg poslovanja?

Komentari
Nema komentara. Šta vi mislite o ovome?