Claude Code Auto Mode: Autonomno programiranje uz ljudsku kontrolu
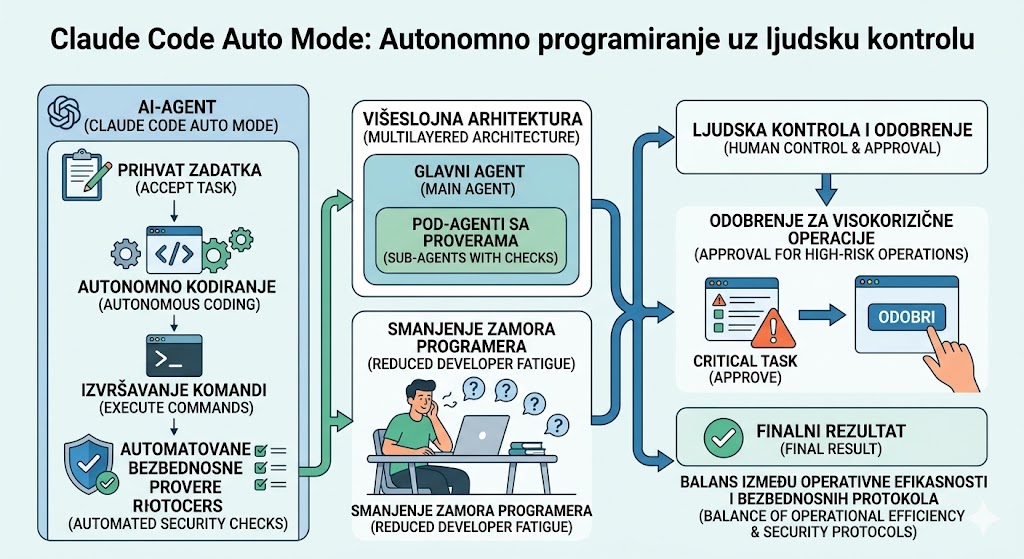
Ovaj tekst detaljno opisuje Anthropic-ov novi "Auto Mode" unutar sistema Claude Code, koji omogućava veštačkoj inteligenciji da samostalno izvršava složene programerske zadatke. Tehnologija uvodi automatizovane provere sigurnosti i višeslojnu arhitekturu kako bi se smanjila potreba za stalnim ljudskim nadzorom i potvrdama. Dok sistem samostalno upravlja kodiranjem i izvršavanjem komandi, ljudsko odobrenje je i dalje neophodno kod kritičnih operacija sa visokim rizikom. Tekst naglašava prelazak sa modela koji zahteva stalnu pažnju na autonomniji proces, čime se sprečava zamor programera od stalnih upita. Pored toga, objašnjeni su mehanizmi za zaštitu od zlonamernih upada i provere unutar pod-agenata radi očuvanja integriteta koda. Zaključno, platforma teži balansu između operativne efikasnosti i bezbednosnih protokola u modernom razvoju softvera.
1. Uvod: Problem "zamora od odobravanja"
Dosadašnje iskustvo rada sa AI alatima za programiranje često je podsećalo na rad sa talentovanim, ali nesigurnim pripravnikom kojeg morate nadgledati svake sekunde. Iako je Claude Code od početka nudio impresivne mogućnosti, ranije verzije su se oslanjale na rigidan model baziran na dozvolama. Svaka shell komanda, svaka izmena fajla i svaki mrežni zahtev zahtevali su manuelni "zeleni signal" od strane korisnika.
Ovaj proces je brzo doveo do fenomena koji mi u industriji nazivamo "approval fatigue" (zamor od odobravanja). Umesto da se fokusiraju na arhitekturu i rešavanje kompleksnih problema, developeri su trošili dragoceno vreme na repetitivno kliktanje i potvrđivanje akcija sistema. Auto Mode dolazi kao direktan odgovor na ovaj izazov, obećavajući promenu paradigme iz mikro-menadžmenta u pravu, kontrolisanu autonomiju.
2. Od "čuvanja dece" do prave autonomije
Uvođenje Auto Mode-a menja osnovnu dinamiku interakcije između čoveka i veštačke inteligencije. Više nije reč o sistemu koji traži dozvolu za svaki korak, već o agentu kojem zadajete cilj, a on samostalno iterira kroz rešenja. Ova promena oslobađa developera uloge "dadilje" koda.
Dnevna rutina se transformiše: umesto da bdite nad terminalom, sada definišete visoke ciljeve i puštate sistem da obavi "prljav posao" generisanja, izvršavanja i testiranja koda. Sid Chaudhary, šef proizvoda u kompaniji Intempt, slikovito opisuje ovu novu realnost:
"Sada možete pokrenuti Claude i zapravo se udaljiti od stola. Pauza za kafu. Prava šetnja. Više ga ne dadiljate."
3. Dvoslojna bezbednost: Pametni filteri umesto ljudskih klikova
Da bi ovakva autonomija bila održiva, Anthropic je implementirao sofisticiranu arhitekturu koja se sastoji od ulaznog (input) i izvršnog (execution) sloja.
Kao analitičari, moramo primetiti da bezbednost ovde ne počiva na jednostavnom filtriranju, već na kontekstualnom markiranju. Ulazni sloj analizira podatke iz spoljnih izvora (poput rezultata pretrage veba). Ukoliko detektuje maliciozni sadržaj ili pokušaj manipulacije instrukcijama, sistem direktno "ubrizgava upozorenja" (injects warnings) u sam kontekst. Na taj način, LLM biva eksplicitno obavešten da su ti podaci nepouzdani, što sprečava da spoljne informacije "otmu" (override) originalnu nameru korisnika.
4. Efikasnost kroz dvostepenu klasifikaciju: SLM protiv LLM logike
Balansiranje brzine i sigurnosti je klasičan problem kod autonomnih agenata. Claude Code Auto Mode koristi proces dvostepene klasifikacije koji podseća na modernu orkestraciju između manjih (SLM) i velikih (LLM) modela jezika.
Prvi stepen je "brzi filter" koji obrađuje rutinske operacije sa minimalnim kašnjenjem. Tek kada se detektuje operacija koja je dvosmislena ili nosi visok bezbednosni rizik, aktivira se "duboka analiza". Sa stanovišta efikasnosti, ovo je briljantan potez: značajno se smanjuju compute cost i latencija, jer se skupi resursi za dubinsku analizu koriste selektivno, bez žrtvovanja ukupne bezbednosti sistema.
5. Crveni "spinner" kao novi vizuelni signal
Transparentnost ostaje ključna, čak i kada je agent "na autopilotu". Korisnički interfejs je evoluirao kako bi pružio jasnu povratnu informaciju o tome kada je AI dostigao granicu svoje autonomije.
Ankit Kalluraya, inženjer testiranja, ističe kako ovi signali olakšavaju rad:
"U auto režimu, spinner (indikator učitavanja) sada postaje crven kada se aktivira provera dozvole, dajući vam jasan vizuelni signal da je Claude zastao i da čeka na odobrenje."
6. AI kao kontrolor: Kriza korporativnog upravljanja
Možda najznačajnija promena je to što AI sada preuzima ulogu "odobravaoca" (approver), a ne samo izvršioca. Mykola Kondratiuk, direktor u kompaniji Playtika, primećuje da ovo stvara ozbiljan organizacioni izazov.
Većina korporativnih dokumenata o upravljanju (governance) i dalje je bazirana na pretpostavci da isključivo čovek može dati finalno odobrenje za tehničku operaciju. Ulazimo u "pravni vakuum": kako ažurirati protokole u svetu gde agent samostalno procenjuje rizik i odobrava sopstvene akcije? Ovo zahteva fundamentalnu redefiniciju pojma "ljudske barijere" u tehnološkom steku.
7. Bezbednost sub-agenata i forenzička "Return Check" provera
Kada Claude delegira zadatke sub-agentima, Auto Mode primenjuje rigorozne kontrole koje idu korak dalje od standardne provere pre izvršenja. Ključna inovacija je "return check" – asinhrona, retrospektivna revizija.
Nakon što sub-agent završi posao, sistem analizira njegovu celokupnu istoriju izvršenja kako bi otkrio "tihe" manipulacije ili prompt injection napade koji su se mogli dogoditi u toku rada. Ovo je svojevrsna forenzička provera koja hvata pretnje koje nisu bile vidljive na početku. Mayank Agrawal, vodeći inženjer u Zethra OS, upozorava na važnu istinu o ovom procesu:
"Ovo je tačka u kojoj se otpornost pretvara u bezbednosni problem."
Agrawal aludira na paradoks: što je agent "otporniji" i uporniji u rešavanju zadatka uprkos lošim ulaznim podacima, to je podložniji suptilnoj eksploataciji ako nema ovakvih rigoroznih povratnih provera.
8. Zaključak: Gde povlačimo liniju?
Claude Code Auto Mode definitivno označava kraj ere u kojoj je AI bio samo napredni autocomplete alat. Anthropic najavljuje dalje usavršavanje modela evaluacije kako bi se postigao još bolji odnos između autonomije i bezbednosti.
Ipak, kao inženjeri i analitičari, moramo sebi postaviti provokativno pitanje: Da li smo spremni da u potpunosti verujemo autonomnim agentima u kritičnim sistemima, ili je "ljudska barijera" nešto što nikada ne smemo potpuno ukloniti? Efikasnost koju donosi Auto Mode je neosporna, ali u svetu gde AI sam sebe odobrava, naša uloga se pomera sa pisanja koda na dizajniranje sistema kontrole koji će sprečiti da "otpornost" postane naša najveća slabost.
Izvor: asdf

Komentari
Nema komentara. Šta vi mislite o ovome?