Sveobuhvatni izveštaj o Z-Image Base (Full) AI modelu:
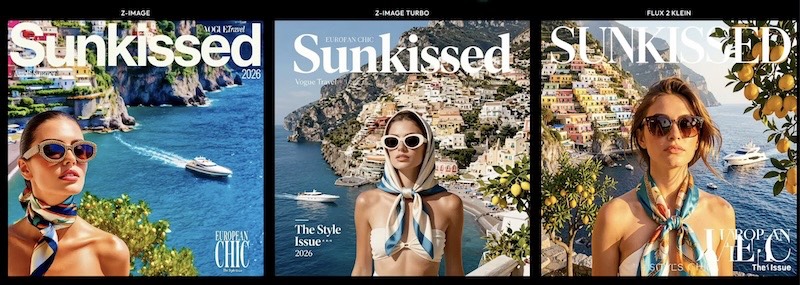
Lansiranjem kompletnog Z-Image Base modela (poznatog i kao Z-Image Full) od strane Alibaba Tongi laboratorije, open-source zajednica za generisanje slika dobila je moćan alat koji značajno unapređuje mogućnosti prethodne "Turbo" verzije. Dok je Z-Image Turbo optimizovan za brzinu i visoku estetsku poliranost, Z-Image Base predstavlja siroviji, "nedestilovan" model punog kapaciteta.
Ključne prednosti ovog modela uključuju drastično veću varijaciju u generisanim slikama, podršku za negativne prompte i superiorne performanse u prepoznavanju poznatih ličnosti i specifičnih umetničkih stilova. Iako zahteva više računarskih resursa (VRAM) i duže vreme za generisanje slika (30–50 koraka naspram 7–9 kod Turbo verzije), njegova prava snaga leži u mogućnosti preciznog finog podešavanja (fine-tuning) i kreiranja LoRA modela. Model je dostupan za lokalno pokretanje putem ComfyUI platforme, sa dostupnim kompresovanim GGUF verzijama za korisnike sa slabijim hardverom.
1. Pregled modela i ključne razlike
Z-Image Base (Full) nije identičan modelu Z-Image Omni Base (koji je još "siroviji" model za generisanje i editovanje), već predstavlja punu, nedestilovanu verziju optimizovanu za svestranost.
Uporedna analiza: Z-Image Base vs. Z-Image Turbo
| Karakteristika | Z-Image Base (Full) | Z-Image Turbo |
| Brzina | Sporiji (30–50 koraka) | Veoma brz (7–9 koraka) |
| Varijacija | Visoka (različite slike za isti prompt/seed) | Niska (sklonost ponavljanju sličnih rezultata) |
| Negativni prompt | Potpuno funkcionalan | Ograničena funkcionalnost (zbog niskog CFG-a) |
| Fino podešavanje | Idealan za trening LoRA modela | Manje pogodan za trening |
| Estetika | Sirovija, ponekad zasićenija ili "plastična" | Visoko polirana, realistični portreti |
| VRAM zahtevi | Visoki (12GB+ za punu verziju) | Manji |
2. Analiza performansi i mogućnosti generisanja
Na osnovu testiranja različitih scenarija, model pokazuje specifične snage i slabosti u poređenju sa konkurentima kao što je Flux 2 Klein.
Snage modela
- Prepoznavanje entiteta: Z-Image Base izuzetno dobro generiše poznate ličnosti (npr. Anne Hathaway, Jackie Chan, Messi) i anime karaktere, što je oblast u kojoj Flux 2 Klein zaostaje.
- Umetnički stilovi: Model briljira u interpretaciji specifičnih stilova, poput impresionizma (Manet stil) i minimalističkog kineskog slikarstva vodenim bojama, gde zadržava autentičnost poteza četkicom.
- Preciznost teksta: Iako nijedan od testiranih modela ne može savršeno generisati dugačke pasuse teksta, Z-Image Base je pokazao superiornost u renderovanju kraćih natpisa na slikama (npr. "Bali Sunset" ili logotip magazina Vogue).
- Raznolikost kompozicije: U grupnim fotografijama (npr. selfi četiri devojke), model pruža veći diverzitet u fizičkim karakteristikama subjekata u odnosu na Turbo verziju.
Ograničenja
- Složenost prompte: Model, kao i većina trenutnih rešenja, ima poteškoća sa preciznim prikazom vremena na satu (npr. "11:15") ili specifičnih nivoa tečnosti u čaši.
- Brzina rada: Vreme generisanja je značajno duže – na testiranom hardveru (RTX 5000 ADA) generisanje traje oko 85–90 sekundi, dok Turbo verzija isti zadatak obavlja za oko 7 sekundi.
3. Tehnička implementacija i lokalno pokretanje
Model se može pokrenuti lokalno koristeći ComfyUI, koji podržava automatsko raspoređivanje resursa (offloading).
Hardverski zahtevi i fajlovi
Za rad sa punom BF-16 verzijom modela potrebne su sledeće komponente:
- Z-Image BF-16 model: ~12 GB (Diffusion model).
- Qwen 34B Text Encoder: ~7.8 GB (Text encoder).
- VAE model: ~327 MB.
Optimizacija za niži VRAM: Za korisnike sa manje od 12GB VRAM-a dostupne su GGUF verzije (kompresovani formati):
- Najmanja verzija (Q2_K) zauzima samo 4 GB.
- Preporučuje se korišćenje najveće verzije koja može stati u raspoloživu video memoriju (npr. verzije od 5GB, 6GB ili 8GB).
4. Napredne funkcionalnosti: Editovanje i Inpainting
Z-Image Base omogućava rad sa postojećim slikama kroz radne tokove u ComfyUI.
- Image-to-Image: Koristeći
VAE Encodečvor, korisnik može pretvoriti skice ili postojeće slike u realistične fotografije. Ključni parametar jedenoisevrednost; vrednost od oko 0.84 u kombinaciji sa CFG-om od 5 daje najbolje rezultate za pretvaranje stilizovanih slika u realizam. - Inpainting (Dorisivanje): Putem
Mask Editor-a, korisnici mogu označiti delove slike koje žele da promene (npr. zamena objekta na stolu). Model uspešno popunjava maskirane oblasti na osnovu novog tekstualnog uputstva.
5. Ekosistem LoRA modela (Low-Rank Adaptation)
Jedna od najvećih prednosti Z-Image Base modela je njegova sposobnost da služi kao osnova za kreiranje novih stilova i karaktera.
Metode treninga
- AI Toolkit (Oris): Tradicionalna i najkvalitetnija metoda koja zahteva prikupljanje i označavanje velikog skupa podataka (dataset).
- Z-Image Image-to-LoRA (I2L): Nova, "brza i prljava" metoda koja omogućava kreiranje LoRA modela za nekoliko minuta koristeći samo 2 do 4 referentne slike, bez potrebe za manuelnim označavanjem.
Napomena: Postojeći LoRA modeli kreirani za Z-Image Turbo nisu kompatibilni sa Z-Image Base modelom.
Zaključak
Z-Image Base predstavlja značajan korak napred za korisnike koji zahtevaju preciznu kontrolu, varijabilnost i mogućnost dubokog prilagođavanja AI modela. Iako njegova brzina i hardverski zahtevi mogu biti prepreka za bazične korisnike, njegova sposobnost razumevanja negativnih promptova i potencijal za fine-tuning čine ga trenutno jednim od najboljih open-source rešenja na tržištu.

Komentari
Nema komentara. Šta vi mislite o ovome?